要我帮设计推荐信息摘要:
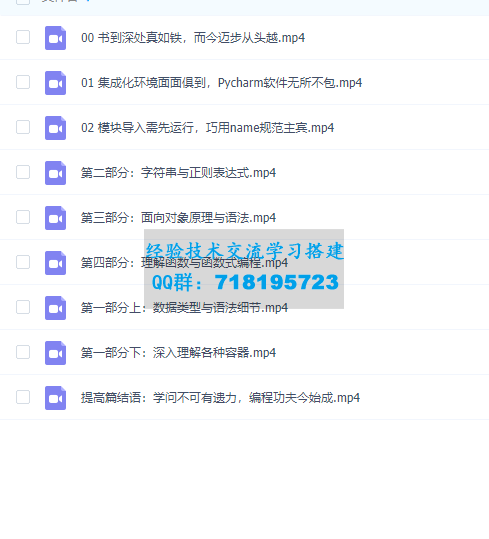
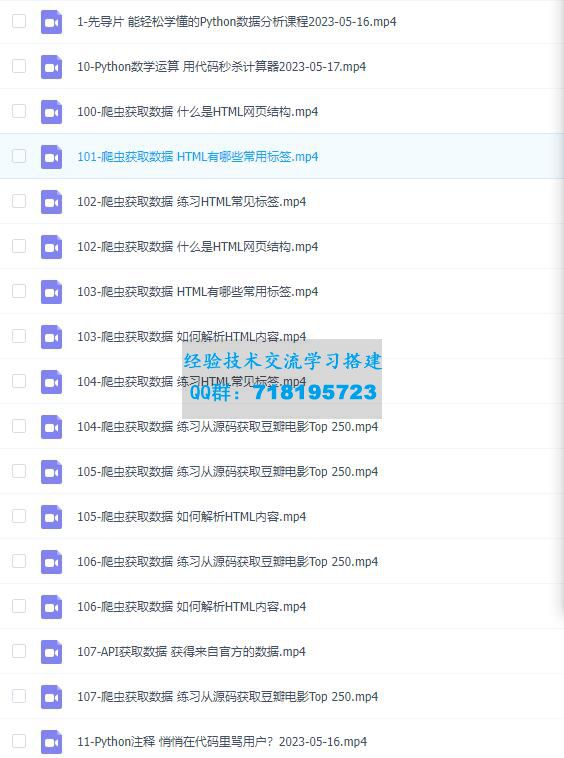
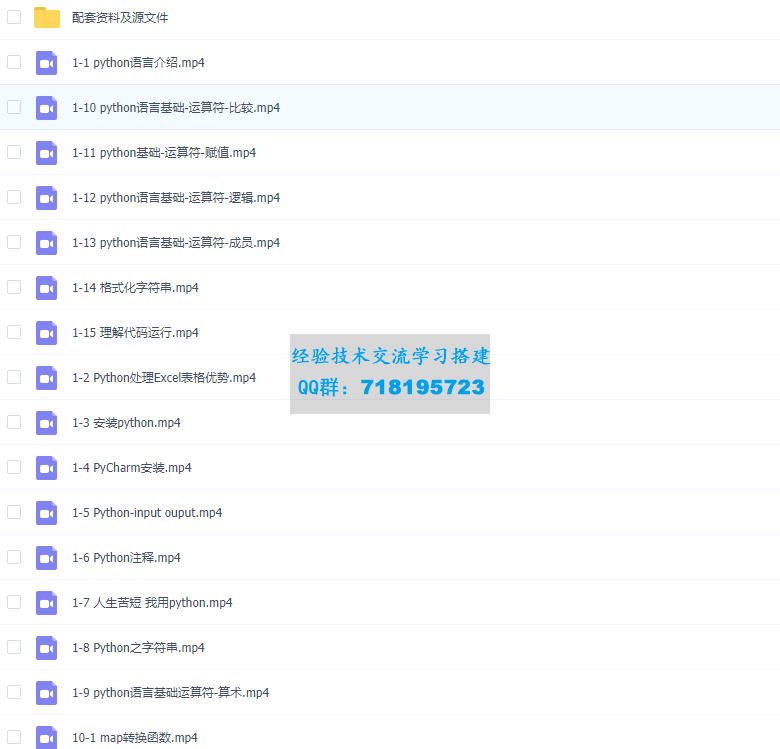
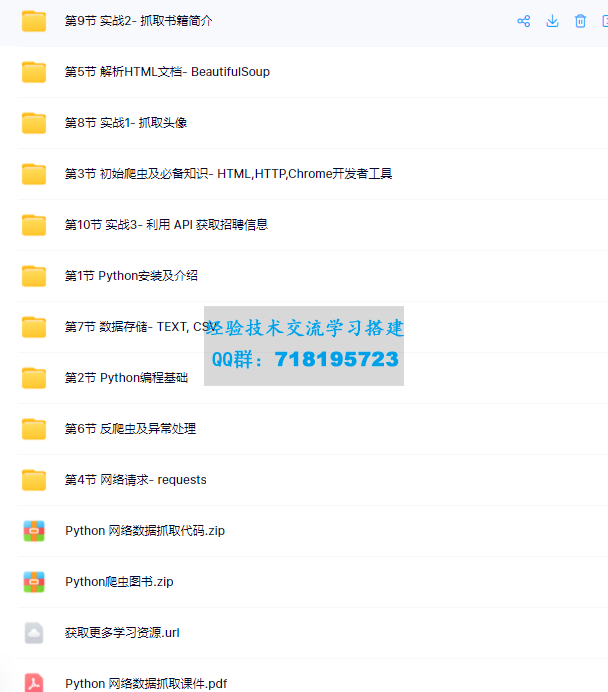
Python 6小时网络爬虫入门课程完整版本课程介绍讲解利用Python语言爬取网络数据并提取关键信息的技术和方法,帮助学习者掌握定向网络数据爬取和网页解析的基本能力。 本课
Python 6小时网络爬虫入门课程完整版
本课程介绍讲解利用Python语言爬取网络数据并提取关键信息的技术和方法,帮助学习者掌握定向网络数据爬取和网页解析的基本能力。
本课程介绍Python计算生态中最优秀的网络数据爬取和解析技术,具体讲授构建网络爬虫功能的两条重要技术路线:requests-bs4-re和Scrapy,所讲述内容广泛应用于Amazon、Google、PayPal、Twitter等国际知名公司。课程内容是进入大数据处理、数据挖掘、以数据为中心人工智能领域的必备实践基础。
课程大纲:
1_【第〇周】网络爬虫之前奏
1.1_“网络爬虫”课程内容导学(00:00:00)
1.2_Python语言开发工具选择(00:03:38)
2_【第一周】网络爬虫之规则
2.1_本周课程导学(00:10:52)
2.2_单元1:Requests库入门(00:12:34)
2.3_单元2:网络爬虫的“盗亦有道”(00:54:20)
2.4_单元3:Requests库网络爬虫实战(5个实例](01:11:54)
3_【第二周】网络爬虫之提取
3.1_本周课程导学(01:39:43)
3.2_单元4:Beautiful_Soup库入门(01:40:51)
3.3_单元5:信息组织与提取方法(02:25:09)
3.4_单元6:实例1:中国大学排名爬虫(02:58:17)
4_【第三周】网络爬虫之实战
4.1_本周课程导学(03:24:21)
4.2_单元7:Re(正则表达式]库入门(03:25:50)
4.3_单元8:实例2:淘宝商品比价定向爬虫(04:15:24)
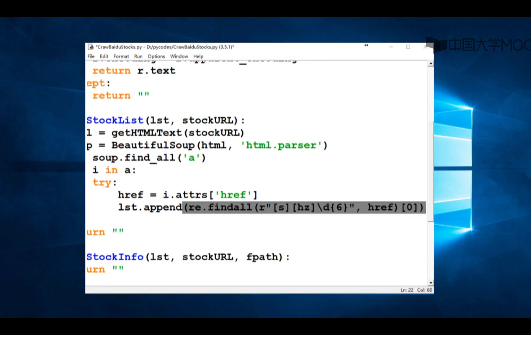
4.4_单元9:实例3:股票数据定向爬虫(04:38:19)
5_【第四周】网络爬虫之框架
5.1_本周课程导学(05:11:05)
5.2_单元10:Scrapy爬虫框架(05:12:02)
5.3_单元11:Scrapy爬虫基本使用(05:37:39)
5.4_单元12:实例4:股票数据Scrapy爬虫(06:06:38)
本网站采用 BY-NC-SA 协议进行授权 转载请注明原文链接:Python 6小时网络爬虫入门课程完整版
本站资源仅供学习研究使用,严谨商用!
如若本站内容侵犯了原著者的合法权益,版权异议/举报。